https://youtu.be/4b5d3muPQmA?si=sA0n1YrxFFx8YhNo
1. Select the number of clusters(=K) you want to identify in your data.
2. Randomly select 3 distinct data points.
3. Measure the distance between the 1st point and the three initial clusters.
4. Assign the 1st point to the nearest cluster.
5. Do the same thing for the remaining points.
6. Assess the quality of clustering by adding up the variation within each cluster.
7. Calculates the mean of each cluster and then reclusters based on the new means.
8. This repeats until the clusters no longer change.
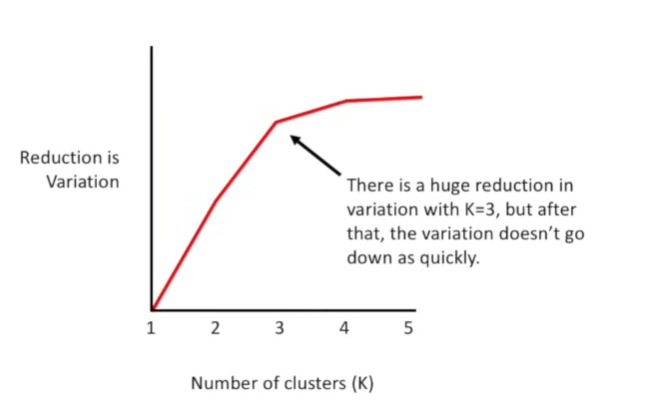
How to figure out what value to use for "K"?
1. try different values for K
2. find an "elbow plot" and pick "K"
KNN vs K-Means Clustering
The key differences between KNN (K-Nearest Neighbors) and K-Means Clustering are:
1. Purpose:
- KNN is used for classification and regression problems.
- K-Means is used for data clustering.
2. Input Data:
- KNN requires a labeled dataset.
- K-Means works with unlabeled, unsupervised data.
3. Working Mechanism:
- KNN finds the K nearest neighbors of a new data point and classifies or regresses based on them.
- K-Means partitions the data into K clusters and iteratively updates the cluster centroids until convergence.
4. Output:
- KNN predicts the class label or regression value for a new data point.
- K-Means outputs the cluster label for each data point.
5. Applications:
- KNN is primarily used for classification and regression tasks.
- K-Means is commonly used for customer segmentation, anomaly detection, data compression, etc.
In summary, KNN is a supervised learning algorithm that makes predictions on new data, while K-Means is an unsupervised learning algorithm that groups data into clusters. They serve different purposes and are used
in different types of machine learning problems.